Insaat 3D Reconstructor goes live
Last several months, I have been working on a side project where I combine 3D computer vision techniques with cloud application development. The result is Insaat 3D Reconstructor, a cloud-native application that makes it easy to reconstruct 3D mesh models from images. This process is also known as photogrammetry.

Photogrammetry | Wikiwand
There are already several software solutions available for this purpose. However, apart from being free, Insaat also offers convenience for the user. In a nutshell, the benefits are:
- You don’t overwhelm your computer with CPU-intensive computations.
- You don’t go through a complex photogrammetry software installation process.
- You don’t need to explore the reconstruction parameter space to fine-tune your reconstruction quality.
The user only uploads the images in JPEG format. When the result is available, Insaat notifies via email, and the 3D model can be viewed in the browser. Because Insaat is not a commercial project, it lacks the powerful hardware to accelerate the computations. Therefore it is targeted more towards 3D model hobbyists rather than industry professionals.
I see it as more of a fun tool. For example, you can create a toy 3D model of your car and 3D print this model to decorate your desk. Or let’s say if you are a landlord in Berlin, you can create a 3D model of your flat interior and share it with prospective tenants.
Technical Overview
Insaat follows a microservices-style architecture consisting of 3 stateless components: webapp, backend, compute.
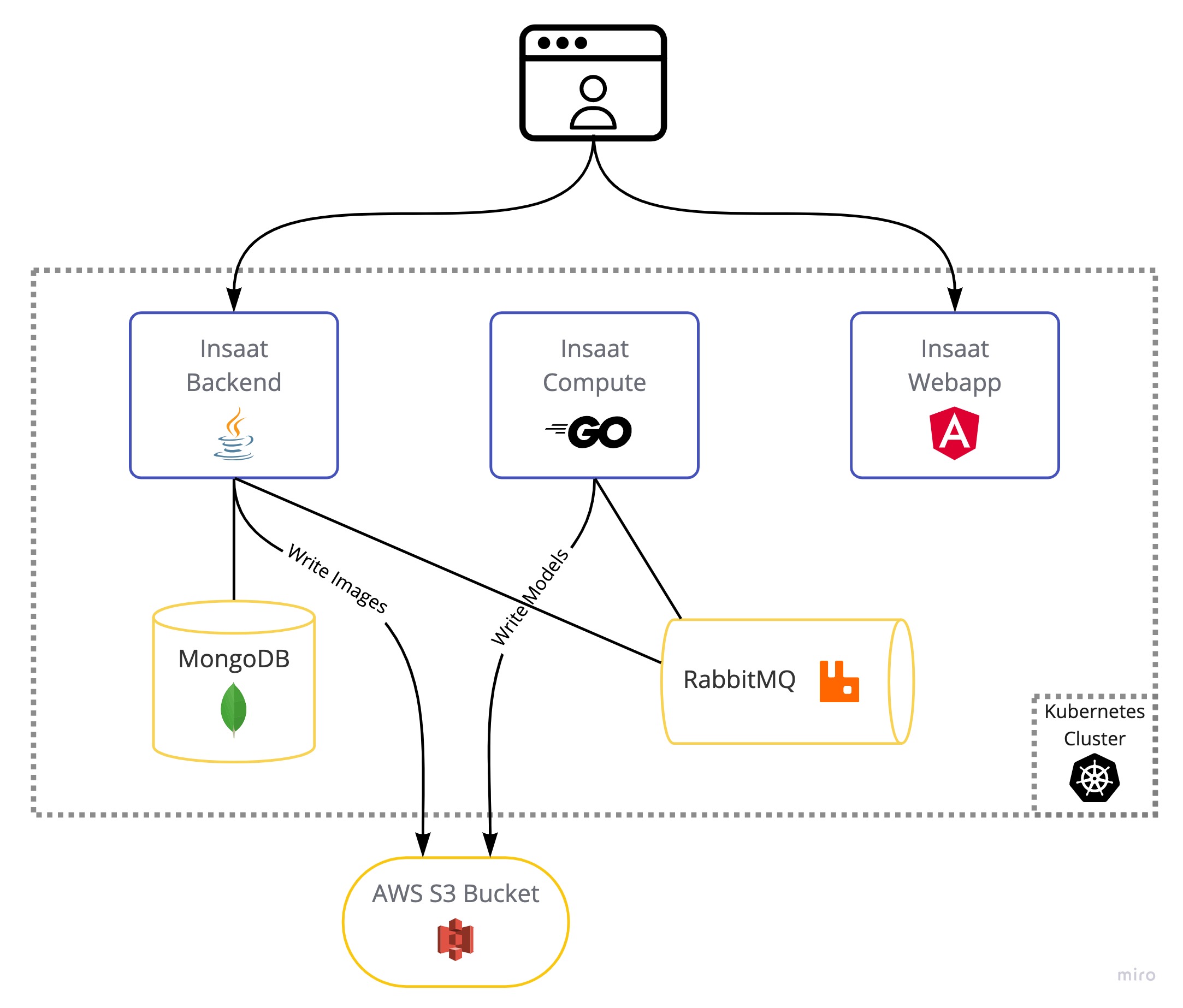
The webapp delivers a single-page application (SPA) written in Angular. This browser client talks to the backend to perform authentication, fetch data, and create new reconstruction requests. These requests reach compute via the message broker, and as the name implies, compute does the heavy lifting by using the OpenMVG complete photogrammetry pipeline. Then, compute publishes the result at the message broker. Throughout the process, binary large objects such as images and models are stored in and served from an AWS S3 bucket.
Challenges
1. Local Development
Right off the bat, I had issues building OpenMVG binaries on my ARM-based computer (M1 Apple Macbook Air). Because many computer vision algorithms lend themselves to parallelization, library authors take advantage of SIMD instructions where possible. However, they seemingly considered SIMD instructions only for AMD 64 architecture CPUs, e.g. SSE, AVX. These are not available in ARM instruction set architecture. Therefore I skimmed through the codebase and disabled parts which use SIMD instructions. I built and published the arm64-based Docker images for OpenMVG and OpenMVS in my Docker account.
2. Building for Cloud Servers
Another similar issue I encountered during the development of Insaat was due to the environment difference between the CI/CD server and the cloud servers. Initially, I built the OpenMVG binaries on the CI/CD machine. Even though the target OS and the architecture (Linux - amd64) matched with the cloud server machine, running the binaries in the cloud would result in a segmentation fault. After some debugging, I found out that the processor in the CI/CD machine included some of the extended SIMD instructions (e.g. AVX-512) which the cloud server did not support. Therefore running those binaries in the cloud server failed since the instructions were not found. I resolved this problem by building the binaries on the cloud server itself.
3. Graceful Compute Service Deployments
I use Kubernetes’ Deployment resource to roll out new versions of the applications. However, during my tests, I noticed that a roll-out of a new compute service would result in lost reconstruction tasks if they were in progress. Which makes a lot of sense because when a SIGINT signal is sent to the containers in the terminating pods, compute service only aborts the child processes and gracefully shuts down. However, it did not have any logic to persist the reconstruction tasks. In the next iteration, I implemented an improved graceful shutdown where the compute service publishes the incomplete reconstruction tasks back to the message queue so that they can be later picked up by the next compute service that will go love and connect to the message queue. It works smoothly in practice.
4. Going Low on Memory
After I got everything working well on my computer I was excited… So with high hopes, I went ahead and did my first reconstruction test on the cloud server. The result? compute pod is killed due to out of memory. Well… after some investigation, I figured out that it never happened on my computer since it uses swap memory. Kubernetes pods? Not really. Allowing swap memory is a feature that is recently introduced in kubelet. While enabling swap could be a solution, I preferred a simpler one. Two ideas to reduce memory consumption:
- Limit the number of concurrent reconstruction tasks
- Resize too large images (also speeds up reconstruction tasks)
After these changes, the peak memory usage never goes beyond 60%, and the reconstructions speed up by a factor of 4. Concretely, a particular reconstruction task that used to take ~5 minutes now takes 1 minute.
Conclusion
I find developing compute-intensive applications in the cloud exciting because there lurk challenges that are not prevalent in typical CRUD applications. Most likely, I am yet to discover more.